

Cricket Data Science 101: Elo Ratings and the Power of DLS Par Score
Sharing some tools for anyone interested in crunching some cricket numbers

Once again, it has been a while since I last posted anything here; I know, it always feel like I start off like this, but life has a way of getting in the way of free-time creative (?) writing. Today, I wanted to have a slightly different take on the ‘science’ of cricket, this time looking at some data science.
While I’m not expecting a huge level of general excitement, there must be some cross-over between people interested in cricket aerodynamics, and those into cricket stats and performance numbers. Plus, it is something different to write about, and keeping things fresh gives me a higher chance to actually finish an article.
For those of you who don’t know, cricket data science is essentially my day job. I analyse numbers, slice up data and build visuals, mainly for the ECB, but also for a few other teams. While my actual data science skills aren’t all that, having an in-depth knowledge of how cricket works allows you to see patterns in data or model outputs that can actually influence how the game is played from a strategic or tactical standpoint.

This is where my idea for sharing some simple ideas and tools came in. I have had the pleasure of working with some amazing Performance Analysts in English cricket, who know cricket better than anyone, but don’t necessarily have the time or resource to build their own tools. I am fortunate enough to have proper data science colleagues who know much more than me about statistical theory and machine learning, and while I am learning from them, I hope to be able to help others out too.
So, I’m going to cover a couple of basic data science principals and show some simple examples. My aim was to mimic some of the tools provided by big sports data companies without the need for powerful computers, machine learning degrees or costly third-party subscriptions.
All you need is a laptop and an appetite for getting stuck into numbers. I’ll show you how to run some simple Python scripts, with the aim for all outputs to be sent to spreadsheet files which you can open in Excel or your software of choice.
Elo Ratings - Learning from chess grandmasters
The first data science concept we’re going to look at is a ranking system, developed by Arpad Elo, a physics professor and chess aficionado (sadly no connection to the 70’s Brummie pop-fusion sensation).
The idea of an Elo Ranking is that it provides more context than a simple ranking based on win percentage, as it takes into account the quality of opposition and margin of victory. It can also be used to calculate a simple win percentage for two teams pre-match. For more detail, I recommend reading this blog series by Matt Mazzola, containing some of the underlying maths and theory.
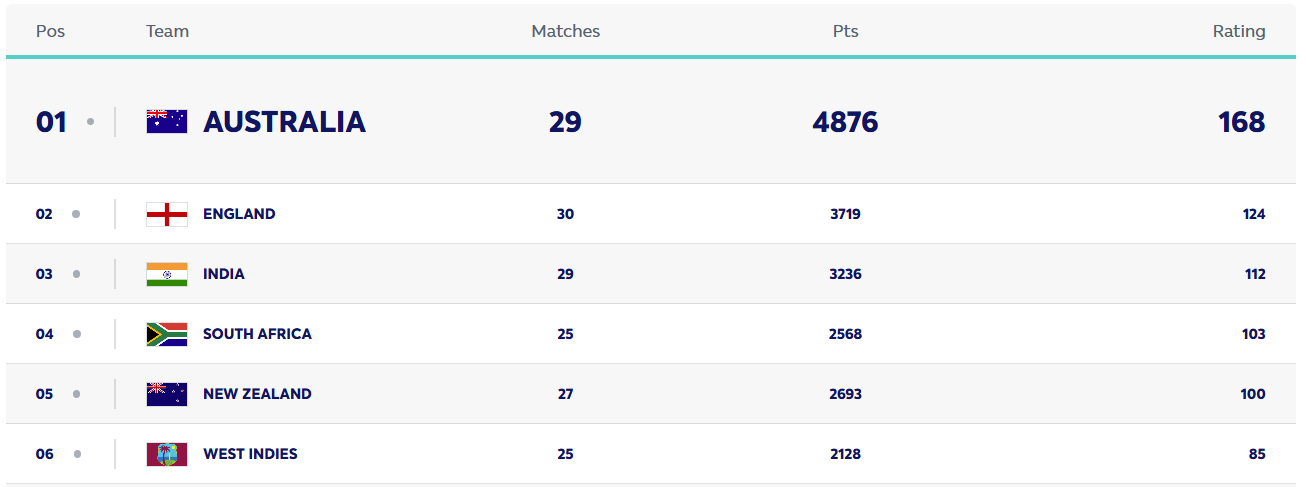
A use-case for Elo Ratings is looking at the current Women’s ODI ratings above. England sit at #2 in the ranks, but were comprehensively beaten in the Ashes in January. While the win/loss pts column clearly shows the gap to Australia, an Elo ranking could be used to give their likely winning chance in their next encounter, and give more of a roadmap for how to close the gap.
The ratings can be used both retrospectively and predictively, and I’ll go through an IPL based example in the next section. But first, here’s a tutorial for running some code from scratch, for anyone who hasn’t dabbled in using Python before.
Setting up and running the Python code to calculate Elo Ratings
What you need are:
A computer you can download Python onto
My Python scripts found on my GitHub
Some level of patience to follow my likely incomplete instructions
Step 1: Download and install Python on your machine
If you already have a Python install, skip this part, and jump to using the scripts or notebook (I’ll assume you know what you are doing). Otherwise, follow this link to download and install the latest version of Python (make sure you include ‘pip’). For those of you not into coding, I’ve tried to make this workflow pretty light on writing code, but it might convince you to have a play around with it in the future.
Once you’ve finished the install, you can test the install by opening the Command Prompt on Windows, or Terminal on Mac or Linux as shown below:

Step 2: Download the Elo Ratings code from GitHub and install requirements
The code to calculate ratings is available here, on my GitHub account. If you follow the link, click on the green ‘Code’ button, and then ‘Download Zip’ to save a local copy. Extract the file to a sensible folder, as we will be navigating to it in Command Prompt.
Go back to your Command Prompt/Terminal window and navigate to the folder you saved the code into (example using the cd command below). Next, check you have ‘pip’, the Python package manager installed, which it should be as standard, using the pip -V command. Then install the required Python packages as shown below:

You should then get a big wall of text as the install takes place; let this run and cross your fingers for minimal errors. This will give you the basic packages needed to run the scripts. (Sidenote, while in general it is best practice to set up a ‘virtual environment’ to install packages and run code, this is a beginner guide, so we’ll install them system wide for now.)
Step 3: Run Jupyter and open the cricket-elo-ratings Notebook
Once the modules are installed, you can run ‘Jupyter’, which is a notebook module, and an easy way to get started running Python code. Making sure you are still in the right directory, run the command jupyter notebook to open up a browser based Python code editor.
NB. When running the code in future after installing everything, you just need to navigate to the right folder and run the jupyter notebook command.
Again, you’ll get a wall of text, and maybe a browser tab will open. If the browser throws an error, copy the URL show in Command Prompt into a fresh tab. Don’t close Command Prompt, but you are done with it for now.

If all is well and good, you should see a Jupyter page in your browser like below, and you are ready to start running some code! Double click on cricket-elo-rating.ipynb to open the notebook in a new tab.

How likely were KKR to win the 2024 IPL final?
The first set of blocks in the code notebook allow us to generate team level Elo Ratings, which can be used to work out comparative ratings and win percentages. The ratings I’ve created use the match result and Net Run Rate (NRR) to calculate the rating change after each game.
You can look at the code in the elo_ratings.py file to see the exact formula but, in general, you get a big rating increase by:
Beating a team predicted to beat you
Beating a team by a big NRR margin
I’ve included an example data set for the IPL 2024 season in the GitHub download, but you can use the code on any dataset you would like. To do this, click on this link above to navigate to ESPN Statsguru, select the matches you want with the same output filter I have set, and click ‘Submit Query’; the output should look similar to below, showing each innings of a game as an individual row.

Next, highlight the table, then copy and paste the values into Excel or similar, and save it as a CSV file (not an .xlsx Excel Workbook). For now, you can also run the notebook code with the default settings to use the pre-downloaded IPL data.
Running the first five code blocks from the notebook, (by hitting Ctrl + Enter or clicking the ‘play’ icon on each one), hopefully getting an output similar to the plot below. This is the rating of each team after each game they played throughout the season. There is also CSV file showing the calculations for each game which is written into the example_outputs folder.
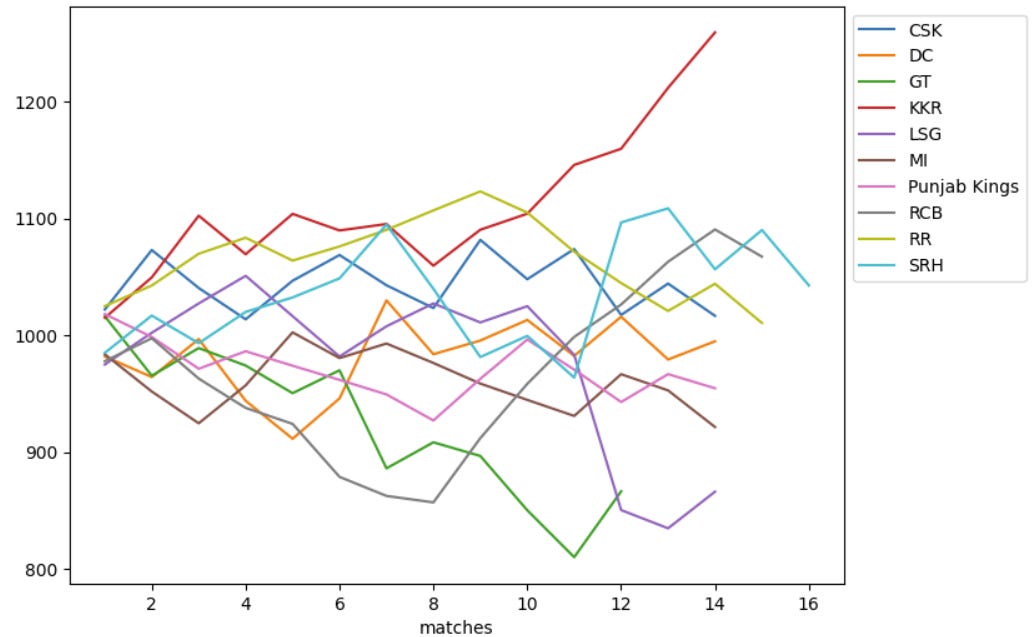
Looking at the CSV export, we can also see the win percentages for each team going into each match. For the 2024 final, KKR had an Elo rating of 1211.8 vs 1090.1 for SRH, giving them a 67% win chance, which is pretty high for a T20 game!
To use this code for your own ratings, simply download a different set of fixtures from Statsguru, save it into the folder, change the filepath in the second code block, and away you go.
Player Level Elo Rankings
The same methodology can be used to calculate player rankings, this time using each delivery as a mini ‘match’ between a batter and bowler. The outcome of every ball is either a win for the bowler or batter, but this is harder to quantify, with no obvious result or net run rate equivalent.
Is a dot ball good for the bowler or batter? How about a single? To answer this, we need some level of expected outcome to rank whether a given result should be counted as a win for which player. This is where proper data companies spend time and money predicting likely outcomes for deliveries, using historic data and loads of contextual information.
For us we can bypass all of this with our old friend the Duckworth-Lewis-Stern (DLS) Par score. While much less sophisticated, it is the easiest way of getting expected run values at a fraction of the effort of big data models.
Calculating expected runs from DLS tables
If you’ve never looked at a DLS table before, it tells you the effective ‘resource’ left for a batting team as a function of wickets and overs for a limited overs match. Say you are on 45 runs at 3 wickets down after 10 overs, vs 45 runs at 1 wicket down after 15 overs, which is a better position? DLS gives you an estimate of that.
In the dls_tables folder there are 3 files containing tables for T20 (taken from this paper), 50 Over matches (the standard one) and a prototype one for Multi-day cricket (which I have made up because you don’t usually have DLS in non-limited overs). The plot below shows the resource distribution (y-axis) for each number of wickets (each line) and overs remaining (x-axis).

For a given over, the expected runs can be calculated using the resource expected to be used, and a manually assigned par score, which I often use as a competition average (which you can look up on Statsguru). The steepness of the curve at various points corresponds to the value of each over compared to the whole innings.
As well as this, the value of a wicket can be calculated from the change between one line and the next. You can see exactly how this works by looking in the code itself, but hopefully the general idea makes sense.
Once we have this baseline, you can compare the actual outcome to the expected runs, to give a positive or negative outcome for the batter and bowler. For example, if the expected runs for a given ball with a par score of 180 is 1.6 runs, then a single would be a win for the bowler by 0.6 runs.
This simple methodology is the same one that goes into complex machine learning models I talked about at the start, such as WinViz and other predictive tools. The fact that both an expected runs model, and a player Elo model can come from something as simple as DLS tables, I think is amazing.
Who were the real IPL 2024 MVPs?
The second half of the notebook lets you run player Elo ratings on ball-by-ball data. Following on from the team level example, the default code looks at the 2024 IPL batters and bowlers. However, you can download a huge array of ball-by-ball data from CricSheet (you’ll want the New CSV formats at the bottom of that page). You can also use data from Play-Cricket Scorer Pro, which is popular in the UK.
Again, you can run the code blocks one-by-one to see how it works. Note, the actual calculating of the ball-level ratings might take some time for a big data set. There is a block to output all of the ratings and ball-by-ball data to CSV as well.
The plot below is the tracker for batters throughout the 2024 IPL tournament, showing cumulative Elo rating vs number of deliveries faced. Each time a batter scores above the expected runs, they go up in rating, and when they score below, or get out, they drop.

It is interesting to note that Virat Kohli, the orange cap winner for most runs, doesn’t appear on the list. This is because the Elo value of runs accumulation is less than scoring fast, and losing wickets are only values negatively in high leverage situations (early on or when there aren’t many batters left).
The dynamic duo of Head and Sharma both come out well, as did Iyer, who came to form at the right time for KKR. Pooran was another player who exploded at the end of the season after being solid through the main body of the competition.
The bowler plot shows one player dominating all season, the great Jasprit Bumrah. Varun Chakravarthy shows an interesting rise after twice dropping below the starting Elo value of 1000, whereas the other 3 bowlers show a steady rise through the tournament, indicating consistency throughout.

There are lots more plots I could show from this data, such as looking at undervalued players, phase data etc, but that isn’t the point of this post. Instead, I hope you take this code away and do something interesting with it yourself!
Statsguru and Cricsheet are awesome free data resources for anyone interested in crunching cricket data, and I’ve tried to design the code to operate on the other data sources I know are out there. I know the code is not particularly comprehensive or sophisticated (I haven’t got round to dealing with extras yet), but I will keep working on this where I can.
Either way, this is an example of how to contextualise cricket scorecard data using a few simple lines of code, and hopefully highlights the range of possibilities that data science has in the sport.
That’s all from me today, if you have any questions, feel free to get in touch via email, LinkedIn or Bluesky and I’ll do my best to get back to you. Enjoy the rest of this year’s IPL, and also the upcoming English county season. Go well, and I hope to be back in your inbox soon.
This is absolutely brilliant. Great guide. Even a complete novice like myself was able to set this up. Thanks Aaron!